Qlean Dataset、AI開発を加速する「テクノロジー対話」の日本語音声データを提供開始
公開日:
AI開発の現場で高品質な日本語データの需要が高まる中、Visual Bank株式会社は、AI学習用データソリューション「Qlean Dataset」の新ラインナップとして、テクノロジーをテーマにした対話形式の音声・テキストデータセットの提供を開始しました。音声認識や対話AIモデルの研究・開発を支援する狙いです。
ポイント
- 1生成AIなど技術テーマを扱う、台本なしの自然な2者間対話
- 2音声認識や対話AIなど、音声とテキストを扱うモデル開発に活用
- 3商用利用可能で権利クリア、企業が安心して導入できるデータセット
Visual Bank株式会社が、同社傘下のアマナイメージズを通じて展開するAI学習用データソリューション「Qlean Dataset」において、「日本語・2話者・テクノロジーテーマトーク音声トランスクリプト」の提供を開始したと発表しました。このデータセットは、テクノロジーやIT分野をテーマにした、日本語話者2名による対話音声とその書き起こしテキストで構成されています。
データセットには、生成AIを含む最新技術や関連ニュース、日常での活用事例といった複数の文脈を含む話題が収録されています。台本に依存しない自然な会話形式で、質問や説明、意見交換などが実際の技術議論に近い流れで行われているのが特徴です。収録時間は合計で約200時間に及び、AI開発の現場で求められる大規模なデータ需要に応えます。
このデータセットは、音声認識(ASR)や自然言語処理(NLP)、音声対話AIをはじめ、音声とテキストを横断的に扱うAIモデルの研究・開発用途での活用が想定されています。具体的には、技術領域に特化した音声対話AIの学習データや、技術系ポッドキャストなどを想定した自動文字起こし・要約モデルの開発、社内ナレッジ共有システムの検証データとしての利用が見込まれます。
「Qlean Dataset」は、商用利用が可能で、すべてのデータで被写体からの同意を取得しており、企業が法的リスクを懸念することなく安全に利用できる点を強みとしています。同社は、権利クリアなAI開発環境の構築を支援することで、データ収集・整備にかかる現場の負荷を軽減したい考えです。
引用元:PR TIMES

O!Productニュース編集部からのコメント
生成AI開発が過熱する一方、日本語の高品質な学習データは依然として貴重です。特に専門分野の自然な会話データは、より高度なAIモデル開発の鍵となります。こうしたデータセットの充実は、国内のAI技術の底上げに繋がりそうですね。
この記事の著者
O!Productニュース編集部


関連ニュース

心の力(EQ)を可視化する「EQキャリア・キャンバス」プレリリース開始

半導体調達の新インフラ「TAYOL」、国内最大級の品揃えで5月25日開始

AIが返信文を自動生成、問い合わせ工数1/10に「SmartContact」正式版

インクレイブ、侵入後の被害拡大をAIが防ぐ「ランサムウェア対策サービス」発表
10Xが「Stailer AIプライシング」正式リリース、AIで価格最適化

Canopus、廃棄物BPOサービス「ゴミカン」刷新で拠点管理を一元化

シェイクとコードタクト、Z世代新人向け育成プログラム「CYCLE」提供開始

アラヤ、神経画像解析向けノーコードクラウド「Araya OptiNiSt」をリリース
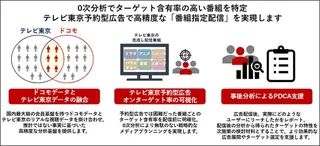
NTTドコモ、1億超dポイントとテレ東視聴データを連携した広告ソリューション開始